I’m not a machine learning engineer. But I work deep enough in systems that when something doesn’t make sense architecturally, it bothers me. And LLMs didn’t make sense.
On paper, all they do is predict the next word. In practice, they write code, solve logic problems, and explain concepts better than most people can. I wanted to know what was in that gap.
I did some digging. And the answer wasn’t that someone sat down and programmed reasoning into these systems. Nobody did. Apparently it emerged. Simple math, repeated at scale, producing structure that looks intentional but isn’t.
But that simplicity didn’t come from nowhere.
Claude Shannon was running letter-guessing games in the 1950s, proving that language has predictable statistical structure.

Rosenblatt built the first neural network around the same time.

Backpropagation matured in the ’80s but computers were too slow and data was too small but the idea kept dying and getting resurrected for decades.
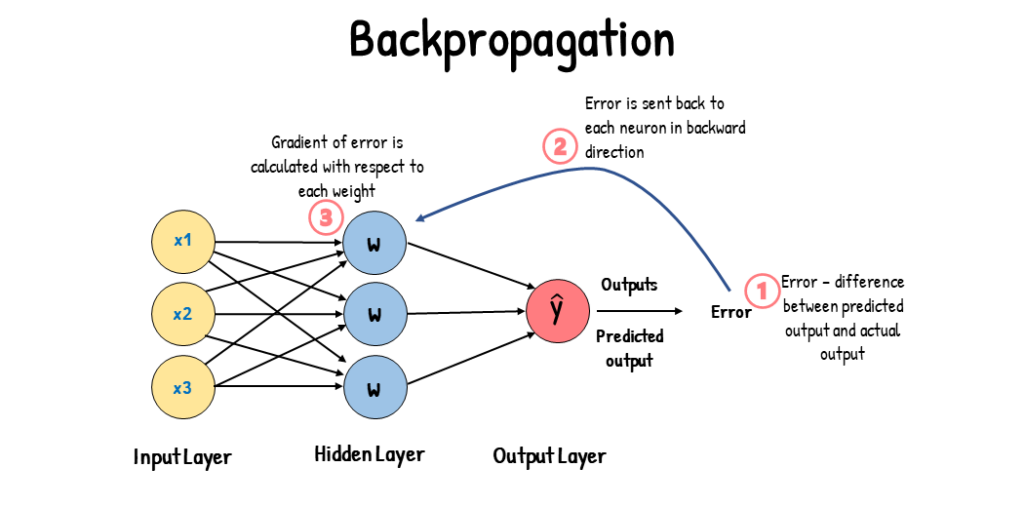
Then in 2017, a team at Google Brain published a paper called “Attention Is All You Need” and introduced the Transformer architecture.
This crystallized the earlier attention ideas into something that scaled.
Not a new idea so much as the right idea finally meeting the infrastructure that could support it.

- GPUs that could parallelize the math.
- High-speed internet that made massive datasets collectible.
- Faster CPUs, SSDs, and RAM that kept feeding an exponential curve of compute and throughput.
Each piece was evolving on its own timeline and they all converged around the same window. GPT, Claude, Gemini, all of it traces back to that paper landing at the exact moment the hardware could actually run what it described.
From what I’ve learned and what I understand, here’s what happens under the hood.
One Moment in Time
The model sees a sequence of tokens and has to guess the next one.
Not full words “tokens”. Tokens are chunks: subwords, punctuation, sometimes pieces of words. “Unbelievable” might get split into “un,” “believ,” “able.” This is why models can handle rare words they’ve never seen whole they know the parts.
It’s also why current models can be weirdly bad at things like the infamous “how many r’s in strawberry” question and exact arithmetic. Because the model reads ‘strawberry’ as two chunks 'straw' and 'berry' it literally cannot see the individual letters inside them.”
But the principle is the same.
Every capability, every impressive demo, every unnerving conversation anyone’s ever had with an LLM comes back to this single act a mathematical system producing a weighted list of what might come next. “The cat sat on the…” and the model outputs something like:
mat: 35%
floor: 20%
roof: 15%
dog: 5%
piano: 3%
...thousands more trailing off into the decimals
Those probabilities aren’t hand-coded. They come from the model’s weights and billions of numbers that were adjusted, one tiny fraction at a time, by showing the model real human text and punishing it for guessing wrong.
The process looks like this:
Let’s take a real sentence “The capital of France is Paris”
Then we feed it in one piece at a time.
- The model sees “The” and guesses the next token. The actual answer was “capital.” Wrong guess? Adjust the weights.
- Now it sees “The capital” and guesses again. Actual answer: “of.” Adjust. “The capital of” → “France” → adjust. Over and over.
Do this across hundreds of billions to trillions of tokens from real human text and the weights slowly encode patterns of grammar, facts, reasoning structure, tone, everything.
That’s pretraining. Real data as the baseline. Prediction as the mechanism. The model is learning to mimic the statistical patterns of language at a depth that’s hard to overstate.
Then we Loop It
One prediction isn’t useful. But chain them together and something starts to happen.
The model picks a token, appends it, and predicts the next one. Repeat.
That’s the autoregressive loop: the system feeds its own output back in, one token at a time.
Conceptually it reprocesses the whole context each step; but in practice it caches(KV cache) intermediate computations so each new token is incremental. But the mental model of “reads it all again” is the right way to think about what it’s doing.
the model can “look back” at everything that came before and not just the last few tokens this is the core innovation of the Transformer architecture.
Older approaches like RNNs, compressed the entire history into a single state vector, like trying to remember a whole book by the feeling it left you with.
Transformers use a mechanism called Attention
which is essentially content-addressable memory over the entire context window each token issues a query and retrieves the most relevant pieces of the past.
Instead of compressing history into one state, the model can directly reach back and pull information from any earlier token
which is why it can track entities across paragraphs, resolve references, and maintain coherent structure over long passages.
It’s also why “context window” is a real architectural constraint. There’s a hard limit on how far back the model can look, and when conversations exceed that limit, things start falling off the edge.
🗨️ Right here, with just these two pieces “next-token prediction and the loop” we already have something that can generate coherent paragraphs of text. No special architecture for understanding. Just a prediction engine running in a loop, and the patterns baked into its weights doing the rest.
But this creates a question: if the model only ever produces a probability list, how do we actually pick which token to use?
Rolling the Dice
This is where sampling comes in.
The model gives us a weighted list.
we roll a weighted die.
Temperature controls how hard we shake it and it reshapes the probability distribution.
🗨️ The raw scores are divided by the Temperature number before being converted to probabilities.
Gentle shake (low temperature) and the die barely tumbles and it lands on the heaviest side almost every time. The gaps between scores get stretched wide, so the top answer dominates. “Mat.” Safe. Predictable.
Shake it hard (high temperature) and everything’s in play. The gaps shrink, the scores flatten out, and long shots get a real chance. “Piano.” Creative. Surprising. Maybe nonsensical.
But temperature isn’t the only knob. There’s also top-k and top-p (nucleus) sampling, which control which candidates are even allowed into the roll.
Top-k says “only consider the 40 most probable tokens.”
Top-p says “only consider enough tokens to cover 95% of the total probability mass.”
These methods trim the long tail of weird, unlikely completions before the die is even cast. Most production systems use some combination of all three.
The weights of the model don’t change between rolls. it’s the same brain, the same probabilities, but different luck on each draw.
This matters because it’s how we can run the same model multiple times on the same prompt and get completely different outputs. Same terrain, different path taken. The randomness is a feature, not a bug.
Run that whole loop five times on the same input and we might get:
Run 1: "The cat sat on the mat and purred."
Run 2: "The cat sat on the mat quietly."
Run 3: "The cat sat on the roof again."
Run 4: "The cat sat on the piano bench."
Run 5: "The cat sat on the mat and slept."
Same model. Same weights. Same starting text. Five different outputs, because the dice rolled differently at each step and those differences cascaded.
Teaching the Model What “Good” Means
Pretraining gets us a model that knows what language looks like. It can write fluently, complete sentences, even produce things that resemble reasoning.
But it has no concept of “helpful” or “safe” or “that’s actually a good answer.” It’s just mimicking patterns. To get from raw prediction engine to something that feels like a useful assistant, we need another layer.
This is where Reinforcement Learning from Human Feedback (RLHF) comes in. which is essentially a feedback loop that turns a raw prediction engine into something with opinions
First, there’s supervised fine-tuning (SFT).
Take the pretrained model and train it further on curated examples of good assistant behavior
- high-quality question-and-answer pairs
- helpful explanations
- well-structured responses
This is the “be helpful” pass. It gets the model into the right ballpark before the more nuanced optimization begins.
Preference optimization stage.
Take the fine-tuned model. Give it a prompt. Let it generate multiple candidate outputs using different sampling runs
same weights, different dice rolls, different results. Then a completely separate model “a reward model”, trained specifically to judge quality reads all the candidates and scores them. “Run 1 is an 8.5. Run 4 is a 4.”
Training: Take that ranking and tell the original model to adjust its weights so outputs like Run 1 become more probable and outputs like Run 4 become less probable.
Nudge billions of weights slightly. Repeat across millions of prompts. Sometimes the “judge” is trained from human preferences; sometimes it’s trained from AI feedback — same destination, different math.
The models we interact with today are the result of all that shaping. One set of weights that already absorbed the judge’s preferences. Often the judge doesn’t run at inference time its preferences are mostly baked into the weights though some systems still layer on lightweight filters or reranking.
Then It Gets Weird
Train a small model to predict the next token and it mostly learns surface stuff: grammar, common phrases, local pattern matching.
"The sky is ___" → "blue."
Exactly what we can expect from a prediction engine.
But scale the same system up with more parameters, more data, more compute and new behaviors start showing up that nobody explicitly programmed.
A larger model can suddenly do things like:
- Arithmetic-like behavior. Nobody gave it a calculator. It just saw enough examples of “2 + 3 = 5” and “147 + 38 = 185” that learning a procedure (or something procedure-shaped) reduced prediction error. Sometimes it’s memorization, sometimes it’s a learned algorithm, and often it’s a messy blend.
- Code synthesis. Not just repeating snippets it saw, but generating new combinations that compile and run.
- Translation and transfer. Languages, formats, and styles it barely saw during training suddenly become usable.
- Multi-step reasoning traces. Following constraints, tracking entities, resolving ambiguity, and doing “if-then” logic over several steps.
The unsettling part to me at least is how these abilities appear.
Some researchers argue these cliffs are partially measurement artifacts, a function of how benchmarks score rather than a true discontinuity.
But the visible shift in capabilities with scale is hard to deny. A model at 10 billion parameters can’t do a task at all. Same architecture at 100 billion, suddenly it blooms into something new.
Like a phase transition
water isn’t “kind of ice” at 1°C It’s still liquid. At 0°C it transforms into something structurally different.
The researchers call these emergent capabilities, which is a polite way of saying “we didn’t plan this and we’re not entirely sure why it happens.” This is why people like Andrej Karpathy openly say they don’t fully understand frontier models. Meanwhile the CEOs selling them have every incentive to amplify that mystique
A human didn’t code a reasoning module. The model needed to predict the next token in text that contained reasoning, so it built internal machinery that represents how reasoning works. Because that was the best strategy for getting the prediction right.
Once researchers realized these abilities were appearing, they started shaping the conditions that strengthen them:
- curating training data with more reasoning-heavy text
- fine-tuning on chain-of-thought examples that show working step by step,
- using preference tuning / RLHF to reward clearer logic and more helpful outputs
The engineering in frontier models is more like gardening than architecture. They’re creating conditions for capabilities to grow stronger. They still can’t fully predict what will emerge next.
Looking Inside
So if nobody designed these capabilities, what’s actually happening in the weights?
This is the question that drives a field called “Mechanistic interpretability”
Here is a great blog post that helped me wrap my head around this
https://www.neelnanda.io/mechanistic-interpretability/glossary
Researchers are opening the black box and tracing what happens inside. The model is just billions of numbers organized into layers. When text comes in, it flows through these layers and gets transformed at each step. Each layer is a giant grid of math operations. After training, nobody assigned roles to any of these. But when researchers started looking at what individual neurons and groups of neurons actually do, they found structure.
Think of it like a brain scan. You put a person in an MRI, show them a face, and a specific region lights up every time. Nobody wired that region to be “the face area.” It self-organized during development. But it’s real, consistent, and doing a specific job.
The same thing happens inside these models.
Take a sentence like “John gave the ball to Mary. What did Mary receive?”
To answer this, the model needs to figure out that
John is the giver and Mary is the receiver,
track that the ball is the object being transferred,
and connect “receive” back to “the ball.”

When researchers traced which weights activated during this task, they found consistent substructures distributed patterns of neurons that reliably participate in the same kind of computation. Not random activation but structured pathways that behave like circuits. One pattern identifies subject-object relationships and feeds into another that tracks the object, which feeds into another that resolves the reference. in reality it looks messier and more distributed than a clean pipeline diagram, but the functional structure is real and reproducible and visually noticeable
it’s a circuit that just naturally emerged due to Prediction pressure during training forcing the weights to self-organize into reliable pathways because language is full of patterns like this
And these smaller circuits compose combine and feed into complex circuits. Object-tracking feeds into reasoning feeds into analogy. It’s hierarchical self-organization layers of structure built on top of each other, none of it hand-designed.
Anthropic published research mapping millions of features inside their model.
Mapping the Mind of a Large Language Model Anthropic
https://thesephist.com/posts/prism/
Nomic Atlas (Visual Representation)
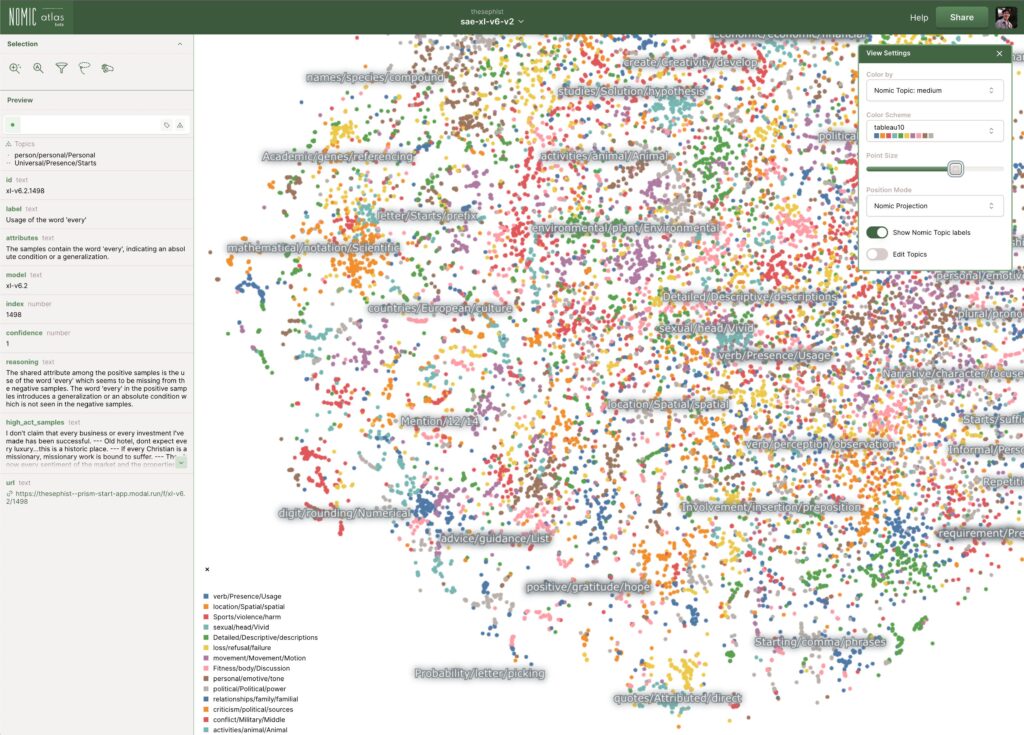
They found individual features that represent specific concepts. Not “neuron 4,517 does something vague” but “this feature activates for deception,” “this one activates for code,” “this one activates for the Golden Gate Bridge.” Mapped into clusters,
Related concepts group near each other like neighborhoods in a city. A concept like “inner conflict” sits near “balancing tradeoffs,” which sits near “opposing principles.” It looks like a galaxy map of meanings and ideas that nobody drew.
some models like DeepSeek (Mixture of Experts) take this further.
They didn’t just develop one set of circuits. They train many specialized sub-networks within a single model and route each input to the most relevant ones.
- Ask it a coding question and one subset of weights fires.
- Ask it a history question and a different subset activates.
The model self-organized not just circuits, but entire specialized regions and a traffic controller to direct inputs between them. Same principle, one level up.
Spirographs and fractals

This is where the overall concept it self clicked for me.
Strictly speaking, neural networks are not closed mathematical loops. Conceptually, however, a spirograph illustrates exactly how they operate:
🗨️ Simple operations, iterated across a massive space, producing complex structure that looks designed but emerged on its own.
A spirograph is one circle rolling around another. Dead simple rule. Keep going and we get intricate symmetry that feels intentional.
Change one tiny thing like shifting the pen hole slightly off-center, change the radius and now we get a completely different pattern.
Training is like that: same architecture, same objective, small changes in data mix or learning rate can yield meaningfully different internal structure.
And like fractals, the deeper we look, the more structure we find. Researchers keep uncovering smaller, sharper circuits. The same motifs repeat at different scales. The interesting behavior lives right on the boundary between order and randomness.
It’s the same pattern we can see in nature: simple rules, iterated, producing shapes that look designed.
Closing out the loop
In school I used to draw circles over and over with a compass, watching patterns appear that I didn’t plan.
Years later, I found myself messing around with Google’s DeepDream feeding images into a neural network and watching it project trippy, hallucinatory patterns back.

I thought I was making trippy images. What I was also seeing was the network’s internal pattern library being cranked to maximum.
The training objective is trivially simple “guess the next word”
But the internal machinery that emerges to get good at that objective ends up resembling understanding.
And “Resembles” is doing a lot of work there whether it’s true understanding, or an imitation so sophisticated the difference stops mattering in practice.
Or maybe it’s simpler than that. We trained it on patterns and concepts and texts created by organic brains which are themselves complex math engines. As a side effect, it took on the shape of the neurons that birthed it. Like DNA from mother and father forming how we look.
Just like we see in mother nature “It’s fractals all the way down”
